Последовательный поиск
Применяется в том случае, если неизвестна организация данных или данные неупорядочены. Тогда производится последовательный просмотр по всей таблице начиная от младшего адреса в оперативной памяти и кончая самым старшим.
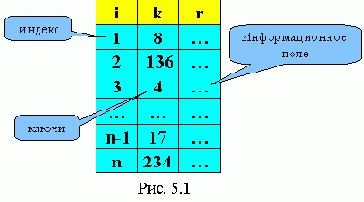
Последовательный поиск в массиве (переменная search хранит номер найденного элемента).
for i:=1 to n
if k(i) = key then
search = i
return
endif
next i
search = 0
return
На Паскале программа будет выглядеть следующим образом:
for i:=1 to n do
if k[i] = key then
begin
search = i;
exit;
end;
search = 0;
exit;
Эффективность последовательного поиска в массиве можно определить как количество производимых сравнений М. Мmin = 1, Mmax = n. Если данные расположены равновероятно во всех ячейках массива, то Мср » (n + 1)/2.
Если элемент не найден в таблице и необходимо произвести вставку, то последние 2 оператора заменяются на
n = n + 1 на Паскале
k(n) = key n:=n+1;
r(n) = rec k[n]:=key;
search = n r[n]:=rec;
return search:=n;
exit;
Если таблица данных задана в виде односвязного списка, то производится последовательный поиск в списке (рис. 5.2).
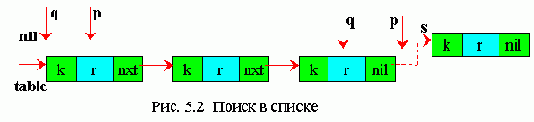
Варианты алгоритмов:
| На псевдокоде:
q=nil p=table while (p <> nil) do if k(p) = key then search = p return endif q = p p = nxt(p) endwhile s = getnode k(s) = key r(s) = rec nxt(s) = nil if q = nil then table = s else nxt(q) = s endif search = s return | На Паскале:
q:=nil; p:=table; while (p <> nil) do begin if p^.k = key then begin search = p; exit; end; q := p; p := p^.nxt; end; New(s); s^.k:=key; s^.r:=rec; s.^nxt:= nil; if q = nil then table = s else q.^nxt = s; search:= s; exit |
Достоинством списковой структуры является ускоренный алгоритм удаления или вставки элемента в список, причем время вставки или удаления не зависит от количества элементов, а в массиве каждая вставка или удаление требуют передвижения примерно половины элементов. Эффективность поиска в списке примерно такая же, как и в массиве.
Эффективность последовательного поиска можно увеличить.
Пусть имеется возможность накапливать запросы за день, а ночью их обрабатывать. Когда запросы собраны, происходит их сортировка.
